GPU 共享四:MIG 带来的补充
原本写完三篇关于 GPU 共享思考之后是可以收声了,奈何昨天核弹黄又在 GPU 共享圈里扔了一颗:MIG。
鉴于 CUDA 11 尚未发布,A100 的 White Paper 也暂无音讯,所以先就着已经发布的 Nvidia 技术博客与大家一起来看看 Nvidia 刚刚发布的支持容器层面共享的 GPU 共享技术。
从硬件出发的彻底隔离
之前 Nvidia 的两种 GPU 共享的方案各有各的问题:
-
GRID 方案可以做到完全资源(算力和显存)隔离,但是必须依托虚拟机,无法在容器上直接挂在分割后的 sub-GPU。
-
MPS 方案可以对接容器(Volta 之后的卡),对算力也能做限制,且无需担心 context switch 带来的 overhead,因为 MPS daemon 将各位 clients 发来的 context 通过 daemon 自身的 context 透传到 GPU。但是受限于硬件,对于显存、IO 带宽,MPS 方案无法做到限制,往往需要额外的组件来处理显存相关的操作。除此之外,之前提到的 MPS context 的错误无法被隔离。这样一来,一个 client 发生了错误,或者说 daemon context 发生了错误,会影响到其他的 client CUDA 程序的运行。
那么 Ampere 带来的 A100 所具备的 Multi-Instance 呢?Reference
MIG 从硬件的层面不仅对 SM(Stream-Multiprocessor,流处理器)进行了分割,还对整个内存系统进行了分割,包括了 Bus、DRAM、L2、Memory Controller 等。这样一来,不同 GPU instance 上的用户程序可以享受不受打扰的显存、带宽等资源。

与此同时,blog 中也提到,新的 QoS 使得单个 instance 上的错误并不会影响到其他 instance 上的 CUDA 程序。这对生产实践助益颇多。
当前 MIG 的分割方案还是比较固定的,一张卡最多可以分成 7 份。当然除了分成 7 份,还有其他力度的分割方案:
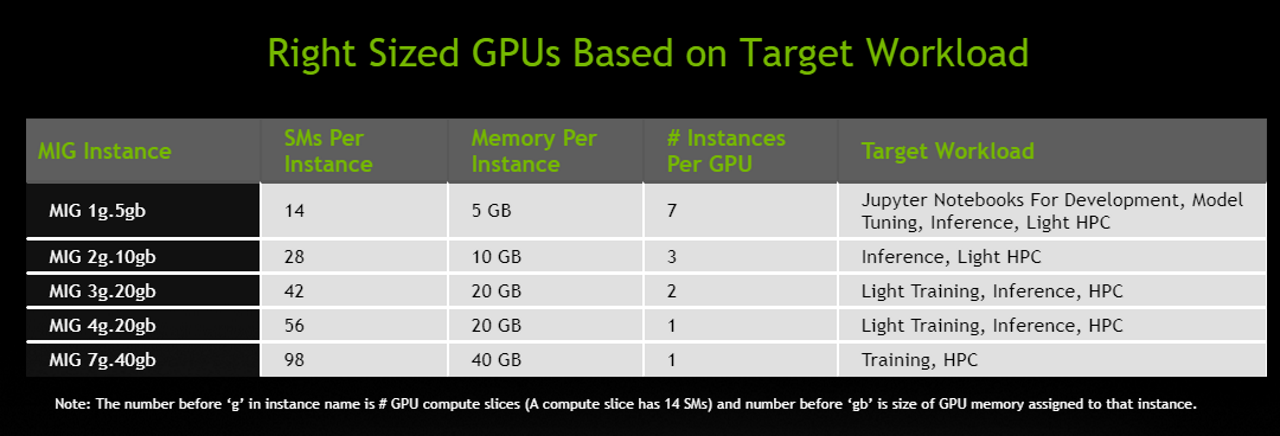
暂时还没想到为什么要像魂器一样分成 7 份,而不是 2^3 份。
鉴于 A100 的庞大算力,即便分成 7 份做一般模型(不是很庞大的模型)的推理服务其实并不划算,可能更多的使用场景还是多用户同时调试模型或直接做小模型的训练。
总体来看,利用 Ampere 这代架构在硬件上的隔离,无论是公有容器云还是私有容器云都可以很快地部署带 GPU 共享的 Kubernetes 集群,并且做到完整的算力、显存隔离而不需要额外的一些组件。
尚未可知的内容
-
[] MIG 是否为 A100 独有,30X0 卡会不会具备 MIG 功能?
-
[] 容器如何选择挂在不同的 GPU instance?
-
[] Blog 中提到的 “a new resource type in Kubernetes” 到底是什么?在 Nvidia device plugin 的 repo 中暂时还没找到相关代码。
有兴趣一起探讨的可以通过我的 email:mailto
后续更新
等到 CUDA 11 和 A100 的 White Paper 发布之后,我会更新这篇介绍。See you then.